
Table des matières
The paperScanner python command
Introduction
PaperScanner is a python command to extract body text of printing character page picture (bad or not).
You can use this command with option python paperScanner.py –help to have more information.
Installation
Download the source code on github https://github.com/hiergaut/opencv/blob/master/paperScanner.py
Of course you need to have opencv library,
some additional lib : PIL and pytesseracct to recognize character.
pip install Pillow
pip install pytesseract
Usage
python paperScanner.py –read <FILENAME>
FILENAME is your picture file that you want to recover text character.
Explanation of source program
Crop and rotate target paper
Firstly we have a picture of text page like this

and we have to retrieve all sentence of this text.
So before apply image treatment operations, I want to crop only the body text and align it.
I need to find the four corner of page before use warpPerspective function,
to eliminate other color unlike the white page, I use histogram to exclude other colors
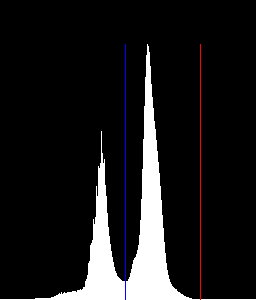 On histogram, there are two peak, on left this is the yellow color chair,
On histogram, there are two peak, on left this is the yellow color chair,
and the other is the page color, seem as yellow more white that the precedent,
is not a perfect white page.
I find the two boundary with this code
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) hist = cv2.calcHist([img], [0], None, [256], [0, 256]) # search max value on histogram M = hist[0] i = 0 for j in range(1, 256): cur = hist[j] if cur > M: M = cur i = j if i > 253: prev = hist[i] else: prev = hist[i] + hist[i + 1] + hist[i + 2] # search first grow up on the right for j in range(i + 15, 254): cur = hist[j] + hist[j + 1] + hist[j + 2] if cur >= prev: break prev = cur right = j if i < 2: prev = hist[i] else: prev = hist[i - 2] + hist[i - 1] + hist[i] # search first grow up on the left for j in range(i - 15, 2, -1): cur = hist[j - 2] + hist[j - 1] + hist[j] if cur >= prev: break prev = cur left = j
after that, I make the contours, I see clearly the quadrilateral, and find the corners.

match = cv2.approxPolyDP(cnt, 0.02 * len(cnt), True) [[p], [p2], [p3], [p4]] = match zoom = 1 w = zoom * int(cv2.norm(p - p2)) h = zoom * int(cv2.norm(p - p4)) if w > h: t = w w = h h = t pts = np.float32([[p4], [p], [p2], [p3]]) else: pts = np.float32([[p], [p2], [p3], [p4]]) pts2 = np.float32([[w, 0], [0, 0], [0, h], [w, h]]) M = cv2.getPerspectiveTransform(pts, pts2) img2 = cv2.warpPerspective(img_src, M, (w, h))
the result :

Treatment (Thresholding, blurring, etc)
So now we must treat text character before launch tesseract recognition I remove the margin to remove folding
h, w = img.shape[:2] margin = 100 img = img[margin:h - margin, margin: w - margin]
Treatment to improve the quality and the sharpness of character
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) img = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
Character Recognition
finally I use tesseract and check if each word exist in a language text dictionary
img2 = Image.fromarray(img) txt = pytesseract.image_to_string(img2, lang='fra') file =open('frenchWord.txt', 'r') keyword_list = file.read().split() cpt =0 for word in txt.split(): if word in keyword_list: print(word) cpt +=1 nbWord =len(txt.split()) print("\naccuracy = ", cpt, '/', nbWord, ' ', "%.1f" % (cpt *100 /nbWord), "%")
after ten seconds, I find 34.4% correct French word in the text.
